Data Quality as a Service: Practical Guide to Implementation by Sundara Rajan PA and Sankara Narayanan

The most prevalent form of delivery for data quality products and the functions they deliver is via on-site implementation, typically via client-server architecture.
But how do you implement a data quality management approach that leverages the Cloud?
In this paper, Sundara and Sankara provide a practical guide for implementing data quality as a service via a cloud based architecture.
Included in this guide:
Component architecture of a Data Quality SaaS proposition
How to layer a DQ SaaS architecture
Role of metadata
Functionalities and services
Introducing Data Quality as a Service (DQaaS)
This guide details architecting data quality as a service.
We will explore the customers of data quality service and the behaviors / qualities they look for.
Then we we will look at how these layered services can be provided through data quality process flows and associated component architecture.
Data Profiling through Exploratory Data Analysis and Mining
Data Monitoring through Data Quality Process Flows configured with Data Quality Business Rule Checks and thresholds to trigger event invocations for closed loop process control, and Data Cleansing are the three major processes available for Data Warehousing, Master Data Management, and Data Migration Customer Requirements.
Fine grained services of lower level components and repositories are also exposed for real time integration in transaction processing environments.
By offering Data Quality as a service, data quality controls can be enforced across the enterprise including on-premise and on-demand (SaaS/cloud based) systems and even outside the enterprise for the customers and partners.
Metadata, in the form of workflows, business rules, and analytics on the profiling and cleaning processes, become available in repositories that can be used for further insights, and business process reengineering.
Where does Data Quality fit in?
Data Quality involves data profiling, validation, cleansing and stewardship services.
These were done in operational systems like Order Management, CRM, Billing, etc., whenever errors occur during new programs launch or system upgrades, due to improper testing of the program logic or due to errors and unexpected exceptions. It also used to happen while porting old application version of the data not meeting the stricter metadata requirements of the new version. Mergers of antiquated systems with the new system also results in data quality issues. This is also applicable to mergers of organizations that eventually result in system integration issues.
When Data Warehouses (DW) were first envisioned to separate transaction workload from reporting and analysis workloads, data quality became the cornerstone in pre-processing the data before the schema level transformations could be done to load them into the DW from transaction systems.
Data Warehousing consists of:
Dimensions or Master Records (Customer, Product, Supplier), and
Facts or Transaction Records (Sales, Purchases)
Data quality is a major component of any Extract-Transform-Load (ETL) program.
It is used in multiple staging data structures and varies from operational data stores, data marts, data warehouses.
Master Data Management (MDM) was the next initiative that promised a single version of the truth across the enterprise and frequently seen as a successor to both Data Warehouse and CRM applications.
Here too, Data Quality is the foundation on which the master data repository is founded.
MDM focuses on Master Data which have comparatively longer life and are more valuable than transactions. These were part of the Dimensions in a Data Warehouse, now they have been re-factored out as a separate component. MDM facilitates not only identity resolution for these master records, but uses statistical data analytics to detect, discover, analyze and reason about relationships between records that will result in house-holding (both personal and corporate), hierarchies and other relationships that will help reduce business risks in identification and consolidation.
Refactoring data quality as a common functionality from these functional components of OLTP, DW, MDM and Data Migration results in configuring Data Quality as a separate component. Its services can be used by the other data architecture components and systems.
This is shown in Figure 1 (Where does data quality fit in?).
There is increased adoption of cloud based on-demand systems like SalesForce CRM in the enterprises. By architecting the Data quality as a service, the consistent set of data quality rules can be applied and re-used across all the systems in the enterprise, including the on-premise and on-demand systems. These services can also be used to validate the data quality of the data shared with the partners and suppliers.
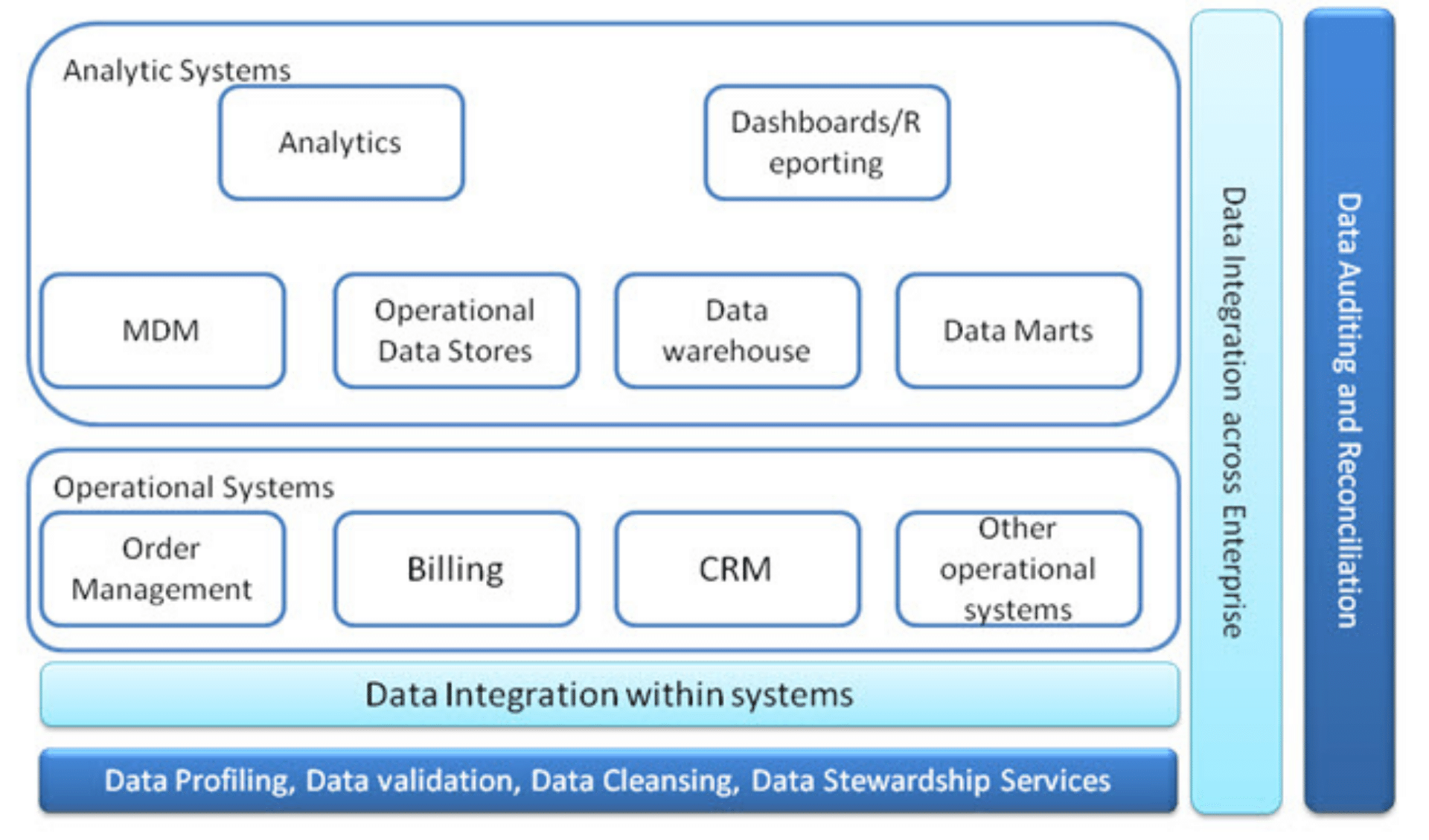
Figure 1 - Where does data quality fit in?
The Data quality services such as Data Profiling, Data Validation, Data Cleansing, and Data Stewardship services will be used in every system within the enterprise. The Data auditing and reconciliation services will be used across all the systems.
Component Architecture of Data Quality as a Service
Data Quality as a service has the following services as shown in Figure – 2 (Component Architecture of Data Quality as a Service).
Data Quality Business Services
Data Quality Technical Services
SaaS (Software As A Service) Infrastructure Services
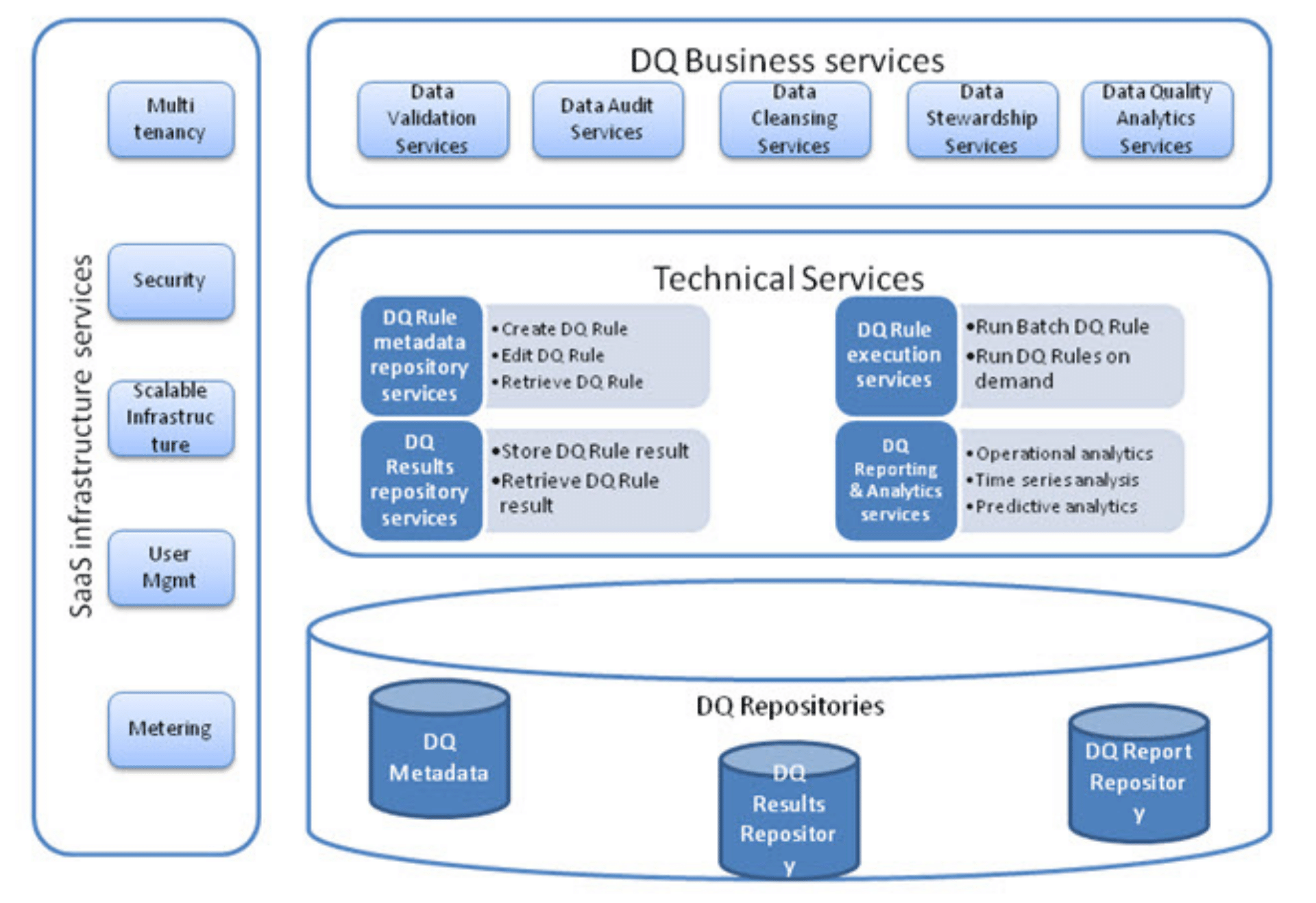
Figure 2 – Component Architecture of Data Quality as a Service
Data Quality Business Services
Data Quality Business Services deal with coarse grained services such as data validation, audit, cleansing, stewardship and analytics services. Validation services run validations against any data set, and provide the audit results for profiling requirements. If cleansing is required, the profiled records are not just tagged, but also corrected for missing, incomplete and incorrect values by various algorithms and external data providers for enriching data.
Stewardship involves conflict resolution and manual overrides where automatic rules are not sufficient to resolve the errors. It also enables integration of data from various sources throughout the data flow life cycle. The data steward is responsible for the metadata rules that are valid for data quality check. The stewardship services include the functionality to assign data stewards for the data sets. Data Quality analytics deal with the operational, time-series and predictive analytics based on the analysis of data quality rules, the data set, and the results.
Data Quality Technical Services
Technical Services are concerned with the Data Quality Rules, the results of enforcing data quality rules, and any analysis and reporting done on the monitoring resultant data.
The Data Quality Rule Metadata Repository Services deal with have a domain specific base of all the rules. The rules are temporal in nature and they could change over time. Their validity is stored so that they can be used to validate data of any period. Data is validated against its metadata or schema which includes its structure, relationships, constraints, valid values and ranges, default values etc.
Over a period of time, domain specific rules accumulated in a rule metadata repository become an asset by themselves, and any executing application can get the services of data quality rule lookup for any specific domain. Thus we can have person naming rules that are very specific to Indian Context with all the family, clan and surnames specific to the region. There could also be another domain specific naming rules pertaining to the United States of America. Data stewards would use a graphical tool to browse, select and modify these rules.
The Data Quality Rule Execution Services are responsible for applying these rules against a data set to get the results into the Data Quality Results Repository Services. The application of these rules might have results in perfectly validated records, or records that are tagged with any corresponding rule violations.
The Rule execution can also result in corrected records, if the configuration allows such cleansing. In extreme cases, the execution of a particular batch could halt to notify a fatal error that ought to be corrected or taken notice of before any further execution could continue. In cases, where a particular organization has developed its own repository of rules, then it might want to just execute those rule sets against their incoming stream of data. In this case, only the execution services might be requested. These rules can be executed in batch or a few of them on demand.
The Data Quality Results Repository Services are responsible for storing the results, both the correct records, tagged erroneous records, cleansed records. These work as storage services and offer to store and retrieve results for that particular data quality rule set. Any further analytics and reporting programs are run on this results repository.
The Data Quality Reporting and Analytic Services run reporting and analysis services on the results of the execution of the rules against the data set. It allows the analyst to see what percentage of the records are correct, and how many errors, what type of errors, what is their severity, whether they have been just tagged, or also corrected for these errors, and what is the final data quality score for each record, and the entire run.
It also helps in drawing any correlations between the error frequency, error distribution, with the domain data set. This is more like value added services on top of the rule checking that is done. This gives insights and overall dashboard view of the data quality run. The analytics services can be operational, time-series and predictive.
SaaS Infrastructure Services
SaaS Infrastructure Services facilitate the DQ services being offered as on demand service.
These services include user management, a scalable infrastructure that can expand as well as contract through fluctuating business cycles, security throughout end to end application integration, and metering for payment commensurate with usage, and multi-tenancy where data are co-hosted on a single server, or kept separate depending on the sensitivity and the option chosen by the customer.
Layered Architecture of Data Quality as a Service (DQaaS)
Data Quality Service Architecture is made up of Stakeholders, the Functionalities (Workflow and Rules) and Qualities they expect in their business Processes, the services the components offer to enable these business processes, their configuration, and the Algorithms and Techniques used to implement these services architecture, and finally the repositories for all these data quality process knowledge.
Data Profiling through Exploratory Data Analysis and Mining, Data Monitoring through Data Quality Process Flows configured with Business Rule Checks and thresholds to trigger event invocations for closed loop process control, Data Clean sing, Metadata Services & Data Quality and Flow Analytics Services are the four major processes available for Data Warehousing, Master Data Management, and Data Migration Customer Requirements.
Customers/Clients
OLTP, ERP, CRM
DW, DM, OLAP
Appliances
MDM
Ad-hoc
One-Time
DQ Business Processes
Data Profiling through Exploratory Data Analysis & Mining
Data Quality (DQ) Monitoring through DQ Flows Configured with Business Rule Checks & Thresholds to trigger Event Invocations for Closed Loop Process Control
Data Cleaning
Metadata Services & Data Quality & Data Flow Analytics Services
DQ Services
All Real Time
Embedded
Validations
Extract, Transform & Load (ETL)
Create, Update, Delete Master Life Cycle Services
Merge
Components
Workflow for cleaning and transformation domain wise
Rules For Master, Transaction data domain wise
Dashboard for Monitoring DQ Workflow Metadata, Event Mgmt
Analytics on Workflow Ops & Feedback Control System
Algorithm & Techniques
Deterministic, Probabilistic, Machine Learning and Hybrid Algorithms
De-duplication & Record Linkages for Master Data
Missing Values
Incomplete Values
Incorrect Values
Config
Data Flows Configuration
Rule-Sets Configuration
Quality of Service Configurations
Locale/ Domain/ Preference Configuration
Repositories
Workflow Repository
Rule Repository
Operations Metadata Repository
Analytics Repository
Role of Metadata
Metadata is very important since the validation is based on the metadata or schema. But the metadata itself is suspect, whether it reflects the ground realities. So as a first step, we validate the metadata against the data present. Then with the findings, we correct and update the metadata to achieve metadata quality. Now with the new enriched value metadata, we’ll validate the entire data set.
Metadata is the data about data, and it is the what, where, how, who of the data. It is classified as business, technical and operational metadata. Business metadata gives the business classifications, definitions and the stakeholder information. Technical metadata gives the schema and other information that resides in the database catalogs, data dictionaries, data integrators and adaptors, mapping information. Operational metadata is about the daily ETL runs the quality measures and the error facts and dimensions.
Data Quality Generic Process based on the Metadata Verification
The following steps are part of data quality profiling, cleansing and monitoring processes.
Formulate policy for conflicting properties to satisfy key constituencies
Define data quality check process flow in terms of sequence of steps
Each step to have the following:
SQL / business rule /component that will do the check
Threshold for event-invocation, alert
Record tagging mechanism – only tagging (or) correction
Data profiling and anomaly detection
Error analytics
All processing is done in memory if possible. Legal and compliance requirements alone dictate parallel recording on disk for the intermediate steps.
While data profiling is a static first time activity to estimate the work, data cleansing is done after the data profiling work yields a positive score to go ahead with the project. Data monitoring is a continuous activity that is used to alert and keep the information systems in proper health.
Phase 1 – Estimation of Work
Exploratory data profiling, analysis, and mining for metadata and data quality.
Gather metadata, business rules from various database repositories, tools, apps
Validate gathered metadata with explored/mined metadata to arrive at validated metadata
Profile the data with the validated metadata
Work out the estimated time, I/O, CPU, disk space requirements based on benchmarks, volume of data and errors reports
Different Cost Options can be provided for Various Combination of Qualities
Sample:
Volume : 2 GB per day ( 10 Mb Masters, 1.99 Tran)
DQ Score : 82% (Masters 90% -Transactions- 75%)
Precision corrected : 98% (Masters – 99.9 %, Transactions – 97%)
Latency : 6 hrs
Multi-Tenancy : Co-hosted with 2 others
Cost : 2 Computing Instances
Phase 2 – Governance and Policy Framework & Process Definition
Manual configurations, decision making, choosing cost, quality etc. are done in this step. Choose the qualities mix between transparency versus corrective, speed versus thoroughness. Choose the action to be performed for each data, as to what should be done: whether to ignore the records, mark them and notify, correct them and notify (or) stop/ halt process and notify.
Phase 3 – Trial Run and Monitoring
Compare with bench-marks, Hand hold, transition, reporting, dashboard, Business Activity Monitoring, DQ business process reengineering, tweaking. Process Analytics for closed loop control System.
Phase 4 – Regular Run, Monitoring, Alerts, Event Invocation Thresholds, SLAs, Cost, BPR Cycles
This phase indicates a steady-state where the data quality programs are regularly watched for exceptions monitoring and continuous improvement.
Phase 5: Change Management
This phase involves addition of other data sources, changes in input data quality observed due to system upgrade or mergers and acquisitions, and any other changes to cost, and quality models.
Customers and their Business Processes:
1. OLTP Application (ERP, CRM, etc.) & Real Time Services
They will embed these data quality services at a fine grained level in their applications at the time of data entry for Real Time Data Quality Check.
2. Data Warehouse (DW)
a. On-Premises
b. Cloud Offering
3. Domain Specific OLAP Appliances & Data Marts
a. Do not store but only process in a pipe-line architecture, need data quality services as a filter before analytics.
4. Master Data Management (MDM)
During master data creation, enforce data quality rules, perform data cleansing, standardization, reconciliation.
Accordingly, it calls Identity Services for that particular master data to validate for duplicates and authenticity.
5. Data Migration, Go-Live, Enterprise Information Integration in Mergers, Ad-hoc, and Real Time Services
They will use individual services, or access a component or a repository at a finer grained level. They may also be a one-time activity.
Qualities:
Conflicting Qualities of Volume of Data, Speed, Accuracy and Complexity have to be prioritized. If Volume of Data is more, it will increase latency, decrease accuracy, and reduce the complexity that can be supported. If latency is to be near real time, then accuracy achievable might be less, complexity that can be supported will be less, and so is the volume.
Generally, the following qualities are specified in various orders of priority and weights.
1. Volume of Data
2. Speed / Latency window available to process
3. Accuracy, Imputing & Enrichment
4. Complexity in Schema Transformation and Integration
5. Security
6. Reliability
7. Scalability as in Cloud availability and SAAS pricing model based on volume, latency, security of data
Modular construction that will enable plug and play, any algorithm, with any other product, with enough adapters for all the industry offerings are an ideal wish list for offering data quality as a service. Customizable workflow with a workflow repository and learning systems that will learn which workflow is best suited for what type of applications characteristics. Customizable rule set with a rule repository and expert systems for data quality rule identification & extraction and machine learning. Choice of algorithms – Deterministic, Fuzzy and Probabilistic, Machine Learning, Hybrid – based on the qualities – should be available by choice for selection.
Architectural Styles/ Configuration used – Design Choices – A Discussion:
There are two architectural approaches – Pipes & Filters and loosely coupled architecture, which includes data audits and on-demand services. Pipes and Filters is the underlying style of the Data Flow configuration of the various components and connectors that form the Extract-Transform-Load (ETL) Data Quality workflow. This allows configurable, learnable, monitorable architecture.
The data flows through these pipes and filters can follow the process control style, where there is a repository for these workflows both for profiling and data cleansing. We should be able to measure the data quality of the input data, and in process data. According to the output data qualities required by the customer we should be able to tweak the process to select deterministic, probabilistic algorithms to effect complete or approximate and converging data quality measures. This should form a closed loop feedback or feed forward control system.
The components, services, business processes are organized hierarchically in layers. While inner layer functionalities are carefully exposed as finer grained exports, the business process layer implements the data flow processes as a virtual machine over the finer services. This layering also helps design based on increasing levels of abstraction. The data quality rules and workflow are configured with thresholds and events are invoked when a data set violates that threshold. Some components are called by Implicit Invocation to selectively broadcast to interested alert, messaging and reactive components. Repositories are used as central data structures that represent the current state, and a collection of independent components operating on it. The states of the repositories also trigger some data quality processes.
In the loosely coupled architecture, the data quality controls are not embedded in the ETL processes. This architecture is applicable for the Data audits or reconciliation processes. For e.g. the counts of the source and target systems are taken and compared against a set threshold in this scenario.
Functionalities and Services:
Domain Specific Services:
1. Identity Services (Person, Product, Business, Location)
2. Granular Contact Services (Address, Name and Phone)
3. Name , Phone, Address Services
4. Relationship Verification Services
a. Hierarchy
b. Supplier Verification in the Industry, for Competition, and not Sub-contractor to another supplier
c. Customer Verification for Credit, Competition
Standard Services for Data Profiling Analysis & Data Quality Enforcement:
1. Column Property, Structure, Simple & Complex Data Rule, Value
2. Column Nullity, Numeric and Date Ranges, Length Restrictions, Explicit Valid & Invalid Values
3. Checking Table Row Count, Column Distribution, Data Rule, and Value Rule Reasonability
4. Matching, De-duplication, Reconciliation, Standardization for Data values and Structures
5. Metadata ( Business, Technical, ETL Generated Operational Metadata)
Acknowledgements:
The authors would like to thank S V Subrahmanya, Vice President, E-com Research Labs, Education and Research at Infosys Technologies Ltd, for his mentoring and valuable inputs regarding process flow data architecture concepts, and Anupama Nithyanand, Lead Principal, E-com Research Labs, Education and Research at Infosys Technologies Ltd for her multiple and extensive reviews through various revisions and valuable comments, in addition to inputs on data governance and master data management.
The authors would like to acknowledge and thank the authors and publishers of referenced papers and textbooks for making available their invaluable work products which served as excellent reference to this paper. All trademarks and registered trademarks used in this paper are the properties of their respective owners / companies.
References:
1. Alex Berson and Larry Dobov [2007]. “Master Data Management and Customer Data Integration for a Global Enterprise”, Tata McGraw-Hill Publishing Company Limited.
2. Allen Dreibelbis, Eberhard Hechler, Ivan Milman, Martin Oberhofer, Paul van Run, Dan Wolfson [2008]. “Enterprise Master Data Management: An SOA Approach to Managing Core Information”, Dorling Kindersley (India) Pvt. Ltd.
3. Jack E. Olson [2003]. “Data Quality: The Accuracy Dimension”, Elsevier.
4. Mary Shaw and David Garlan [1996]. “Software Architecture: Perspectives on an Emerging Discipline”, Prentice-Hall, Inc.
5. Ralph Kimball and Joe Caserta [2004]. “The Data Warehouse ETL Toolkit”, Wiley Publishing, Inc.
6. Tamraparni Dasu and Theodore Johnson [2003]. “Exploratory Data Mining and Data Cleaning”,John Wiley & Sons, Inc.